ESOMAR ANA
A smart AI search platform that gives ESOMAR members instant insight across decades of research
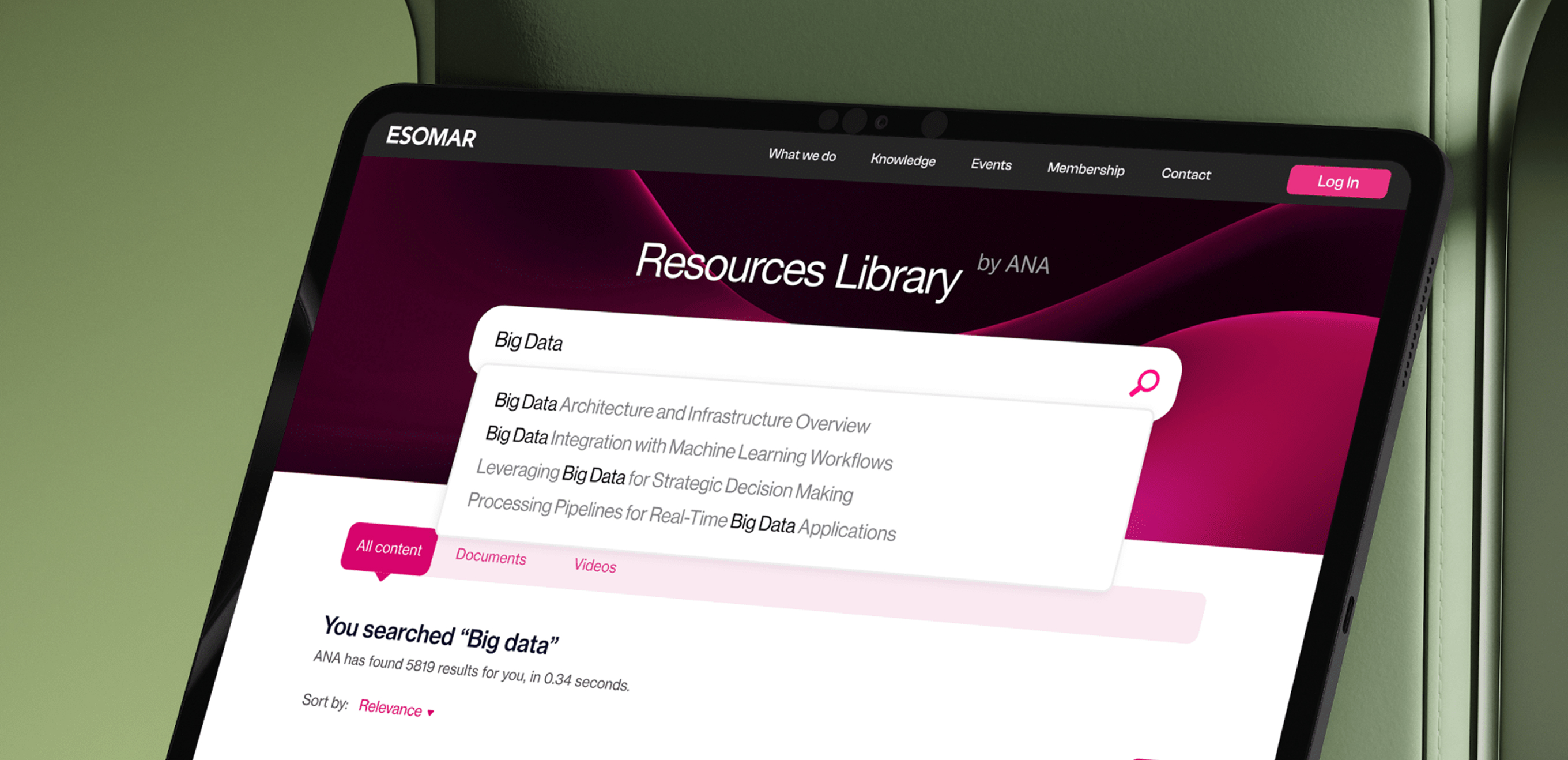
ANA is an AI search platform that lets ESOMAR members instantly explore decades of research, insights, and publications. It turns a massive knowledge base into clear, fast answers that support better decision making across the global research community.

ESOMAR holds one of the most comprehensive bodies of knowledge in the global research industry. Decades of reports, guidelines, case studies, frameworks, and event papers sit inside a huge archive that members rely on for decisions. The problem was access. Traditional search could not interpret research language, connect ideas across documents, or surface insights buried deep inside PDFs. Members often knew the information existed, but not where to find it.
ESOMAR needed a smarter way to unlock this entire archive. A tool that understands industry terminology, merges insights from multiple documents, and answers questions the way a researcher thinks.
We built ANA, an AI powered knowledge engine that turns ESOMAR’s entire library into an instant, conversational experience. ANA interprets natural language questions, scans thousands of publications, and generates clear, citation backed answers. Members can explore topics, compare perspectives, upload their own documents, or dive into the exact sources behind every response.
ANA is now a core part of ESOMAR’s digital offering, giving the global research community fast, reliable access to the full depth of ESOMAR’s intelligence.
Strategic objectives
Turn your idea into a production-ready product built for growth

Unlock ESOMAR’s full knowledge base through AI search
Give members instant access to decades of research, guidelines, and global insights in one place.
Deliver accurate, citation backed answers
Ensure every response is grounded in verified ESOMAR publications so users trust the output.
Reduce research time across the industry
Turn hours of document searching into seconds by understanding context, terminology, and research language.
Support deeper decision making for researchers
Enable users to explore topics, compare perspectives, and analyze insights with multi document reasoning.
Expand ESOMAR’s digital value for members
Strengthen the membership offering with a powerful AI tool that enhances daily research workflows.
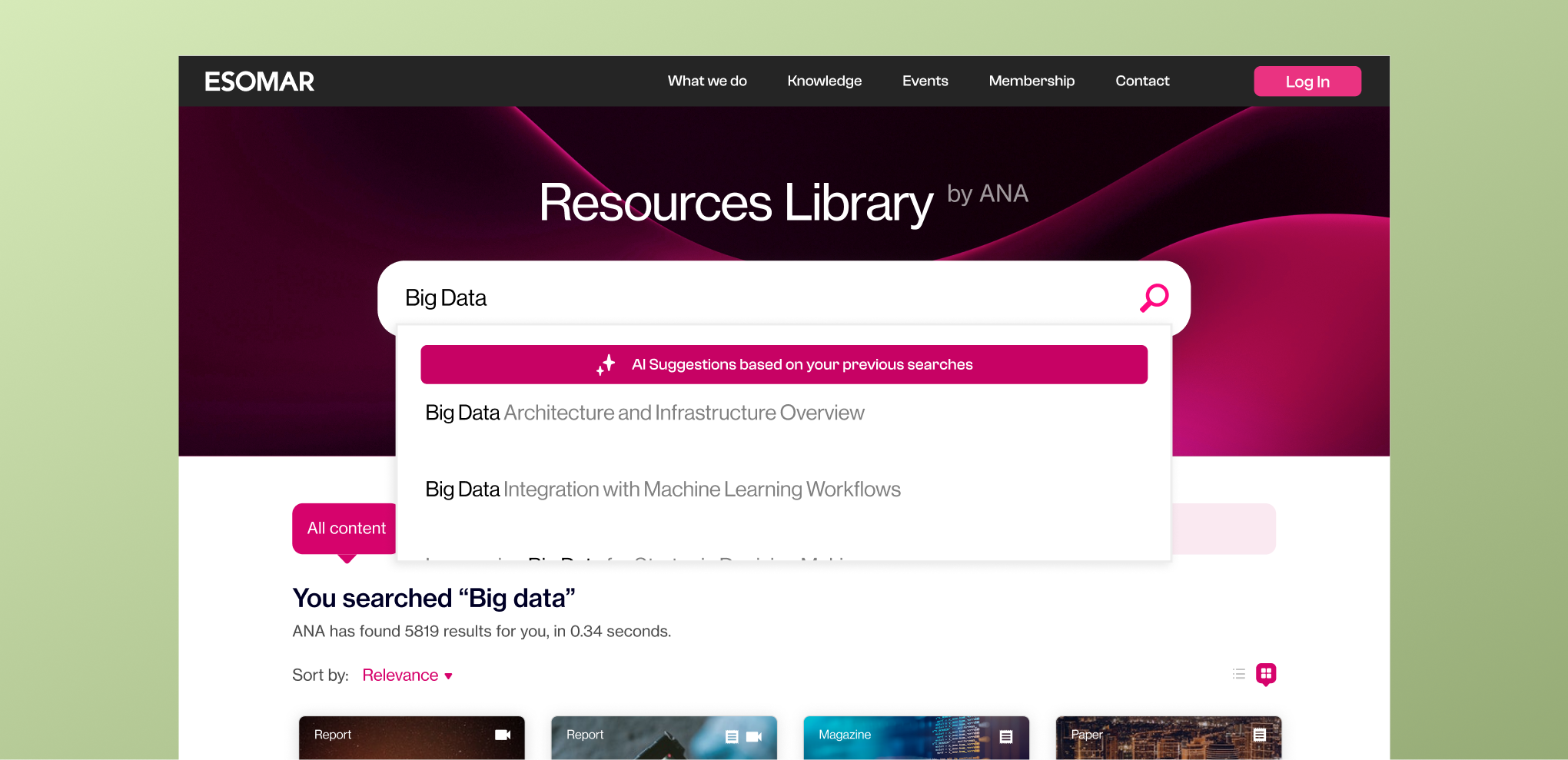
Most prominent features
Conversational AI search
Ask natural language questions and receive clear, synthesized insights instantly.
Citation backed answers
Every result includes linked sources so users can verify information quickly.
Full ESOMAR archive indexing
Search across decades of reports, guidelines, papers, and publications in one query.
Multi document reasoning
ANA merges insights from multiple documents to give a complete, contextual answer.
Document analysis
Users can upload their own files to extract insights or generate summaries.
Research aware understanding
Optimized to understand industry terminology, methodologies, and research specific vocabulary.
Saved answers and sharing
Users can store important answers and share them with teams or stakeholders.
Secure, private processing
Uploaded content is isolated and processed securely, respecting ESOMAR’s standards.

The real world impact of turning decades of ESOMAR intelligence into an instant, AI powered search experience
Faster access to critical insights. Members reduce hours of searching by getting instant, AI synthesized answers.
Higher trust in research outputs. Citation linked responses ensure every insight is verified against authoritative sources.
ANA expands ESOMAR’s digital offering and enhances the daily workflow of researchers worldwide.
Product Development Process
The development of ANA started with a simple question. How do you make decades of ESOMAR knowledge instantly accessible to every member, regardless of how complex the topic is or where the information sits. ESOMAR’s archive is massive. Reports, guidelines, event papers, publications, regulatory documents, methodologies, and industry frameworks all stored in different formats and written across different eras. Finding the right insight meant digging, scanning, guessing keywords, and opening dozens of PDFs. We needed to replace that workflow with something fast, intuitive, and accurate.
We began by mapping the structure of ESOMAR’s content. What kinds of documents exist. How they relate to each other. How members think about topics. How researchers phrase questions. This helped us design a system that could interpret intent instead of relying on basic keyword matching. The first prototype focused on question understanding and clean document retrieval. It was intentionally narrow, built to validate one thing. Could the system understand a member question and surface the right source within seconds.
From there, we expanded into multi document reasoning. ESOMAR content is often fragmented across several papers, so ANA needed to merge insights into a single answer. We trained the system to read multiple documents at once, extract the relevant pieces, and present them as one unified response with linked citations. This was tested against real research questions from ESOMAR members to make sure the reasoning held up.
We kept the interface simple. A clean layout, quick access to sources, and the ability to switch between summarized answers and full documents. Researchers move fast, so the product had to stay out of the way. Every design decision supported clarity, trust, and speed.
Security was built in early. Members needed to upload their own documents confidently, knowing the system would process them privately and isolate them from the public ESOMAR archive. We built a secure document pipeline that respects organisational boundaries and handles sensitive files safely.
As ANA matured, we refined the model with real usage patterns. Which questions were common. Where the model struggled. How users validated answers. These insights informed continuous improvements to accuracy, tone, and retrieval quality.
Technical Approach
ANA is built on an AI architecture designed to understand research language, retrieve the right information from ESOMAR’s archive, and generate answers that members can trust. The core technical foundation combines three layers: intent understanding, retrieval, and verified synthesis.
At the retrieval layer, ANA indexes ESOMAR’s entire library of reports, guidelines, publications, and event papers. Every document is processed, structured, and linked to metadata so the system can locate relevant content quickly and accurately. This ensures that answers always originate from ESOMAR’s verified sources, not external data.
The reasoning layer allows ANA to merge insights across multiple documents. Research topics often span several papers or guidelines, so the system is trained to extract relevant sections, compare perspectives, and synthesize them into a single, coherent answer. Each answer includes citations and direct links to the underlying sources to maintain transparency and trust.
The natural language layer is optimized for research specific terminology. ANA understands industry concepts, methodologies, and global market language, allowing users to ask questions the way they think about their work. This goes far beyond basic keyword search and supports deeper exploration across themes and frameworks.
Security is handled with strict isolation. Uploaded documents are processed within a private environment, stay separate from the public archive, and are accessible only to the user who uploaded them. This protects sensitive content and allows ANA to support individual research workflows securely.
The interface is designed around clean interaction and fast access to sources. Users can switch between answers, citations, document previews, and summaries without friction.
Methodology
Our methodology for building ANA focused on one goal. Turn a complex, decades-old archive into a simple and reliable search experience that researchers trust. Instead of designing a generic AI assistant, we grounded every step in how ESOMAR members actually look for information, interpret insights, and validate sources.
We began by studying how researchers interacted with ESOMAR’s content. Which documents they used most. How they phrased questions. How they moved between topics. These patterns shaped the foundation of ANA’s question understanding and retrieval flow. The first iterations were tested with real queries taken directly from member use cases, allowing us to validate whether the system understood intent rather than just keywords.
From there, we moved into rapid cycles of refinement. Each release focused on increasing accuracy, improving source retrieval, and strengthening the quality of the synthesized answers. When the model missed context or returned incomplete citations, we adjusted both the data structure and the reasoning logic before expanding the feature set.
User feedback played a central role. We observed how members navigated the interface, how they compared answers to source documents, and where they needed more clarity. This helped us refine the interface into a clean, research friendly workflow that feels natural to use.
We validated every improvement against two criteria. Does it save researchers time, and does it preserve ESOMAR’s authority. If a change did not serve both goals, we removed or redesigned it.
This iterative, research driven methodology ensured ANA became more than an AI tool. It became a trusted, intuitive assistant that fits seamlessly into the daily workflow of ESOMAR’s global community.
Conclusion
ANA transformed how ESOMAR members access and use decades of research. By combining natural language understanding, reliable retrieval, and transparent citations, the platform turns a complex archive into a clear and fast search experience. Members save time, find insights effortlessly, and make decisions with more confidence.
For ESOMAR, ANA strengthens the digital value of membership and positions the organisation as a leader in applying AI to research knowledge. It supports researchers, analysts, marketers, and strategists with a tool that fits naturally into their daily workflow.
The result is a trusted AI assistant that preserves the authority of ESOMAR’s content while giving users an entirely new way to explore it. ANA makes the depth of ESOMAR’s global intelligence accessible in seconds.

“This project demonstrates the power of AI to unlock decades of knowledge and make it accessible to everyone.” –
.webp)